
Neural multi-view segmentation-aggregation for joint Lidar and image object detection
This post is a summarised verions of my Master's Thesis, which I did at Utrecht University and Cyclomedia. The full thesis can be found here.
Intro
Combining different types of data from multiple views makes it easier to perform object detection. Our novel method enables multi-view deep convolutional neural networks to combine color information from panoramic images and depth information derived from Lidar point clouds for improved street furniture detection. Our focus is on the prediction of world positions of light poles specifically. In contrast to related methods, our method operates on data from real world environments consisting of many complex objects and supports the combination of information from recording locations that do not have fixed relative positions.

Contributions
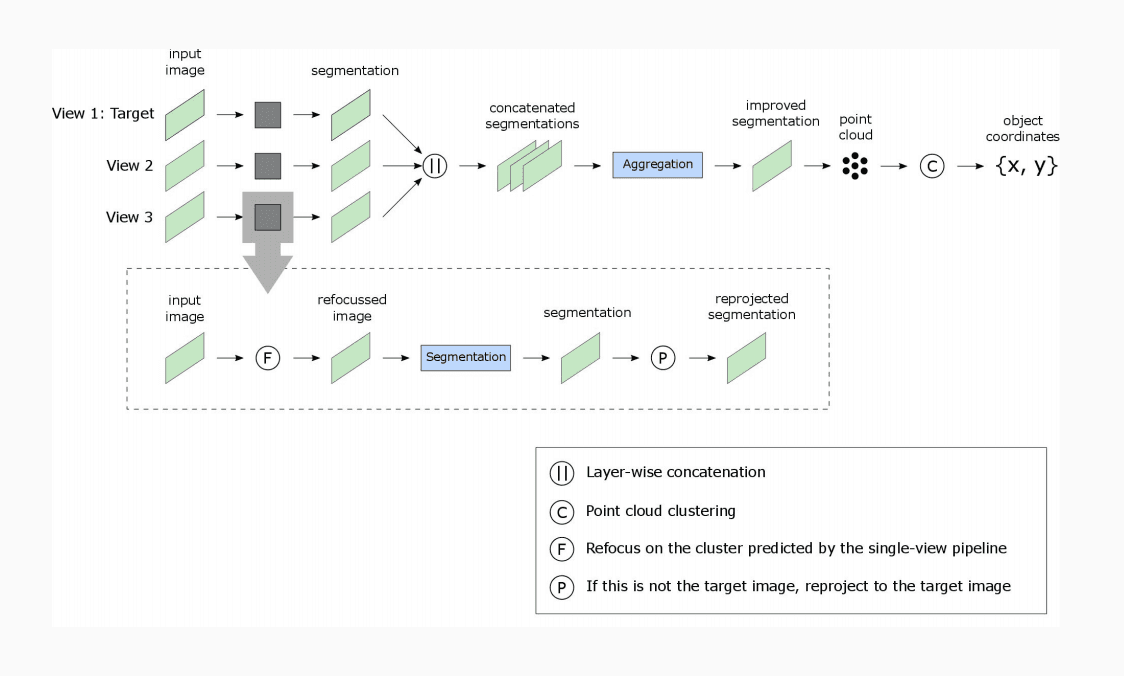
We make five contributions in this work. First, we propose a single-view pipeline which produces segmentations that are reconstructed as labeled point clouds, after which a three-dimensional clustering method extracts the world positions for the segmented objects. Then, a scalable method to generate ground truth to train the segmentation-network is described. Different depth-derived features are explored to find an optimal data representation to transfer information to the neural segmentation-network. A novel method is then introduced that refocuses and reprojects images, based on the depth information of Lidar point clouds, so that correlation between images from different camera poses is directly defined and no longer has to be inferred through complex matching algorithms. Finally, a multi-view pipeline is introduced that leverages refocusing and reprojection to combine data from multiple recording locations. This combination of geometric and deep learning methods has not been performed before.


The single-view pipeline
A neural segmentation network is used to predict pixel-wise labels on our input images. The pixels corresponding to the "light pole" class are then reconstructed as 3D points. A three-dimensional cluster extraction method is applied to extract the clusters corresponding to the light poles. By computing the centroid of each cluster a real-world position is predicted. This single-view pipeline is tested using images with color information, depth information and a combination of both. It is shown that better segmentations generally result in better clustering and world position estimates, although noise can be significantly reduced during the clustering step. Results show that a single-view pipeline using solely depth-information outperforms a pipeline with only color information. The pipeline performs best when operating on the combined representation. Alternative depth representations have been explored but proved ineffective due to limitations in the neural network architecture.


Reprojection and Refocusing
Pixels are geometrically related to directions. Since our data consists of panoramic images, we have information in all directions. In our refocusing step, a new image is created for every object location predicted by the single-view pipeline. Then, the images are resampled in such a wat that the potentially interesting object is brought to the center of the view. Through this process, the views from multiple recording locarions are all focussed at the same object. The views therefore have a high amount of mutual information, and therefore a high correlation. How the pixel information from one view is related to that of another view is however not obvious. First a target view is chosen. Using the per-pixel depth information, the information from the other views can the first be reconstructed as 3D point clouds, and is then projected onto the target image. The result is that the information from multiple views, with varying relative positions, can then easily be correlated; every pixel in the target image is directly related to the same pixel in the reprojected image.


The multi-view pipeline
In the multi-view pipeline, refocusing and reprojection are used to combine the predicted class probabilities over multiple recording locations. Two different methods for the actual combination of probabilities into a single segmentation are explored. The first method embeds a second neural network to learn the importance of each view. The second method simply sums the probabilities from the different views. While the second method generates segmentations that are visually more pleasing, the first method better predicts the positions of light poles. The multi-view pipeline, operating on color information only, correctly predicts 66% of all light poles.

Conclusion
This work has illustrated that a combination of depth and color information improves object segmentation. By refocussing, reprojectng, and aggregating multiple views, segmentations can be further refined. The method is easily extensible to other types of street furniture objects and currently utilizes neural network architectures with relatively small computation and memory requirements. However, the pipeline does not dictate any specific neural network architecture and can in the future easily be updated with more modern networks for improved performance.
This method has since become the cornerstone for many object detection pipelines at Cyclomedia.
Supervisors
Dr. Ir. Ronald. W. Poppe - Utrecht University
Dr. Ir. Bas Boom - Cyclomedia
Arjen Swart - Cyclomedia